Node.js 应用日志切割原理与踩坑实践
2020-05-09

图片来源:https://medium.com/encored-technologies-engineering-data-science
本文作者:夏银竹
引子
2019 年初的时候,我们业务组上线了一个新的 Node.js 应用,主要提供C端的 API 服务。 随着应用流量的逐渐增加,线上监控平台会偶发性报警,提示磁盘 disk_io 平均等待时间超出 1000ms,随后观察发现磁盘 IO 每秒写字节量突然飙高,但很快又下降。
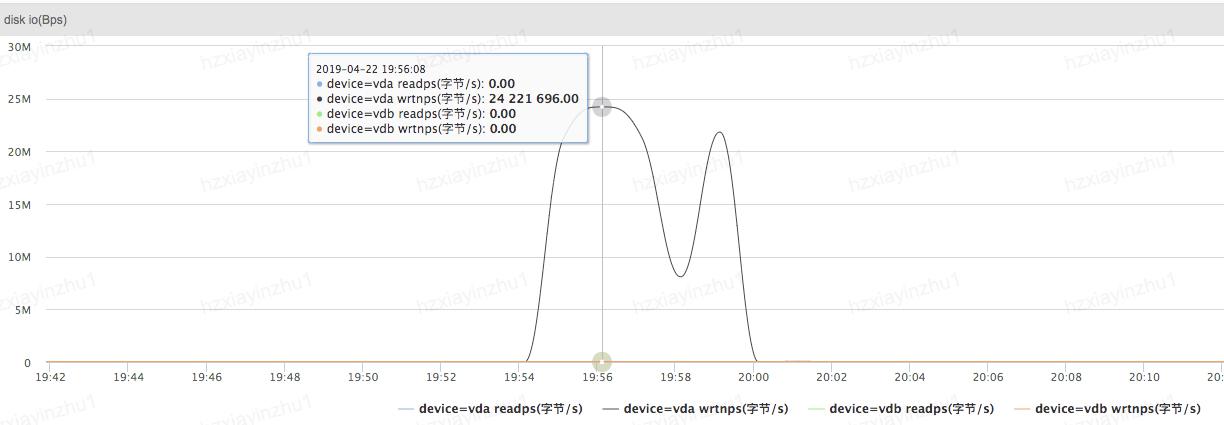
具体的监控图表如上所示,线上 Node.js 应用向磁盘写入数据的唯一场景就是打印日志,通过iotop、ps 等命令也验证了该异常正是由于 Node.js 的日志切割进程导致的。
可是为什么日志切割会引起这么诡异的 IO 问题呢?在揭开谜底之前,我们先聊一聊 Node.js 应用日志切割的原理。
日志切割原理
为什么需要日志切割
日志打印是 Node.js 工程服务化过程中一个必不可少的环节。日志文件中包含了系统运行过程中的关键信息,常用于故障诊断和系统的性能分析。
在日志打印的过程中通常会遇到两个问题:
- 随着时间的积累,日志文件大小会逐渐增长,系统磁盘的空间会被消耗得越来越多,将面临着日志写入失败、服务异常的问题。
- 服务的日志默认存储在单个文件中,自定义查看历史某个时间段的日志将会变得比较困难,期望日志文件能够按照一定的规则切割,以便于排序和筛选。
所以,在生产环境中通常会采用日志切割来解决上述的问题。日志切割可以限制日志文件个数, 删除旧的日志文件,并创建新的日志文件,起到“转储作用”。
实现机制
不同的日志切割组件会采用不同的实现机制,常见的有以下两种:
-
copytruncate 模式:
- copy 当前日志文件,重命名为新的日志文件,这样进程还是往老的日志文件写入。
- 对老的日志文件进行 truncate 清空,这样就完成了一次日志切割。
-
sign 通知模式:
- 首先重命名当前进程正在输出的日志文件名称。因为日志文件是用 inode 来在磁盘上标识,更改日志文件名称并不会影响 inode 号,进程依旧会往修改了名称的日志文件内输出日志。
- 创建新的日志文件,文件名称和老的日志文件名称保持一致。因为是新建的文件,inode 号不一样。此时进程日志还是依旧输出到老的被重命名了的日志文件里面。
- 对进程发起信号通知,让其重载日志的配置文件,实现平滑重启,后续的日志就会写入到新建的日志文件里。
日志切割组件一般都支持可配置日志切割频率,也有两种方式:
- 定时切割: 进程启动一个定时任务,到设定时间后切割日志文件。
- 按大小切割:进程定时监控日志文件的大小,若文件超出设定的最大值时进行切割。
Node.js 应用日志切割
对于前端 Node.js 应用来说,根据项目的框架和部署架构,可选择不同的日志切割方案,例如:
- 基于 pm2 部署的 Node.js 应用,可采用
pm2-logrotate实现日志切割。 - 基于 Egg.js 框架的 Node.js 应用,可采用
egg-logrotator实现日志切割。
下面我们详细介绍一下这两种日志切割方案的实现原理。
pm2-logrotate
实现机制
pm2-logrotate 是 pm2 扩展的日志管理插件,适用于 pm2 部署的 Node.js 应用,同时支持定时切割和按大小切割。
可通过如下的命令来设置一些配置参数:
pm2 set pm2-logrotate:<param> <value>其中的关键配置项如下:
-
max_size
日志文件的最大体积,默认值为 10 * 1024 * 1024
-
retain
切割出的日志文件最大份数,默认值为 30
-
dateFormat
日期格式,基于该日期名生成切割出的日志文件名称,默认值为 YYYY-MM-DD_HH-mm-ss
-
workerInterval
按大小切割时,文件扫描的间隔时间(s),默认值为 30
-
rotateInterval
定时切割的时间间隔(支持cron表达式),默认值为 0 0 * * *
对于pm2-logrotate 本身的实现机制,我们探究源码总结出了一些关键的步骤,具体如图所示:
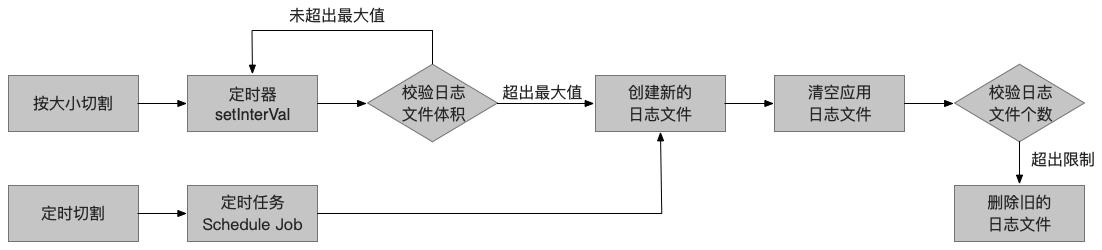
其中切割机制的核心源码如下,从这里我们可以看出 pm2-logrotate 采用了上文介绍的 copytruncate 模式。
// 日志切割的具体过程
function proceed(file) {
// 设置时间作为新的日志文件名
var final_time = moment().format(DATE_FORMAT);
var final_name = file.substr(0, file.length - 4) + '__' + final_time + '.log';
// 创建 read/write streams,将日志写入到新的日志文件中
var readStream = fs.createReadStream(file);
var writeStream = fs.createWriteStream(final_name, {'flags': 'w+'});
readStream.pipe(writeStream);
// 日志写入完毕后, 清空应用的日志文件
writeStream.on('finish', function() {
readStream.close();
writeStream.close();
fs.truncate(file, function (err) {
console.log('"' + final_name + '" has been created');
if (typeof(RETAIN) === 'number')
delete_old(file);
});
});
}IO 异常问题分析
重新回到本文开头的线上问题,由于我们的 Node.js 应用是基于 pm2 实现进程管理,同样也是基于 pm2-logrotate 来实现日志切割。
在排查异常的时候,我们发现了 pm2-logrotate 在实现上的两个问题。
cluster 模式下重复切割日志的问题
通过追溯源码,我们可以确定 pm2-logrotate 会对所有由 pm2 启动的应用进行日志切割。
pm2.list(function(err, apps) {
apps.forEach(function(app) {
proceed_app(app, false);
});
});但是,在 cluster 模式下,pm2 会启动多个相同的 woker 实例,而日志只会打印到同一份文件中。因此,当触发日志切割的条件时,多个 woker 实例会同时对日志文件进行切割,造成 IO 读写繁忙。
同时, copytruncate 模式在日志切割的时候会拷贝原来的日志文件,也会造成系统磁盘使用空间突增。
这个问题在日志文件体积大的时候尤为明显,也是我们 Node.js 应用线上 IO 异常的主因。
为了解决 cluster 模式下重复切割日志的问题,需要对多个 worker 实例进行去重判断,只允许一个实例进行日志切割的操作。具体的判断逻辑可分成两步:
- 判断该实例是否为 cluster 模式下的实例。pm2 给每个应用实例提供了环境变量 pm2env 来查看运行的状态。 `app.pm2env.instances > 1` 则表明有多个相同的实例,可判定为 cluster 模式。
- 判断是否有实例已经做了日志切割。多个 worker 实例的共同点是
app.name应用名相同。因此,每次日志切割的时候新建一个 map 映射表,key 为app.name, 只有当映射表中没有查询到app.name的时候,才会进行日志切割。
代码部分大致如下所示:
pm2.list(function(err, apps) {
...
var appMap = {};
apps.forEach(function(app) {
// cluster模式下的去重判断
if(app.pm2_env.instances > 1 && appMap[app.name]) return;
appMap[app.name] = app;
// 开始日志切割
proceed_app(app, false);
});以上去重判断的逻辑已经提交 PR 并被 merged 。该问题已在 pm2-logrotate v2.7.0 的版本修复。
日志丢失问题
pm2-logrotate 进行日志切割时,新的日志文件名是根据 dateFormat 参数格式化生成的,源码如下所示:
var DATE_FORMAT = conf.dateFormat || 'YYYY-MM-DD_HH-mm-ss';
var final_time = moment().format(DATE_FORMAT);
var final_name = file.substr(0, file.length - 4) + '__' + final_time + '.log';该参数的默认值 YYYY-MM-DD_HH-mm-ss,可以精确到秒级别。在实际生产环境,为了便于检索和查看日志,文件的命名往往会按照按天/小时的维度进行命名。
但是如果 DATE_FORMAT 的格式为 YYYY-MM-DD ,会存在这么一个坑:当一天中应用日志体积多次超出设置的 max_size 后,会出现多次切割的操作,但是每次切割生成的新日志文件名却是相同的。
在已有切割日志的情况下, pm2-logrotate 再次切割时不会判断新的日志文件是否已经存在,而是直接用新切割出来的日志覆盖了之前的日志,从而会导致日志丢失。
// 如果final_name对应的文件不存在则创建,存在则整体内容覆盖
var writeStream = fs.createWriteStream(final_name, {'flags': 'w+'}); 针对该问题的解决方案,一方面可以通过设置 dateFormat 精确到秒级来避免;另一方面,需要评估日志文件的大小,合理设置 max_size 参数,避免频繁触发日志切割。
egg-logrotator
实现机制
egg-logrotator 是 Egg.js 框架扩展的日志切割插件。相较于 pm2-logrotate , 其配置更加灵活,同时支持按天切割、按小时切割和按大小切割。关键配置项如下:
-
filesRotateByHour
需要按小时切割的文件列表,默认值为 [ ]
-
hourDelimiter
按小时切割的文件,小时部分的分隔符号,默认值为 '-'
-
filesRotateBySize
需要按大小切割的文件列表,默认值为 [ ]
-
maxFileSize
日志文件的最大体积,默认值为 50 * 1024 * 1024
-
maxFiles
按大小切割时,文件最大切割的份数,默认值为 10
-
rotateDuration
按大小切割时,文件扫描的间隔时间, 默认值为 60000
-
maxDays
日志保留的最久天数,默认值为 31
具体切割的实现原理如图所示:

其中的核心源码如下,相较于 pm2-logrotate ,从这里我们可以看出 egg-logrotator 则采用了另外一种 sign 通知模式。
// rotate 日志切割源码
async rotate() {
// 获取需要切割的日志文件列表
const files = await this.getRotateFiles();
const rotatedFile = [];
for (const file of files.values()) {
try {
// 重命名日志文件
await renameOrDelete(file.srcPath, file.targetPath);
rotatedFile.push(`${file.srcPath} -> ${file.targetPath}`);
} catch (err) {
}
}
if (rotatedFile.length) {
// reload 重新加载日志文件
this.logger.info('[egg-logrotator] broadcast log-reload');
this.app.messenger.sendToApp('log-reload');
this.app.messenger.sendToAgent('log-reload');
}
}
}
// reload重新加载日志文件
reload() {
this._closeStream(); // 结束当前日志文件流
this._stream = this._createStream(); // 创建一个新的写日志文件流
}优势
就实现方式而言,copytruncate 模式较简单,sign 通知模式则较为复杂,需要有一套完整的通知重启机制。
但是相较于基于 copytruncate 模式实现的pm2-logrotate,基于 sign 通知模式实现的 egg-logrotator 具有两点明显的优势:
- copytruncate 模式在日志切割的过程中需要拷贝原来的日志文件,如果日志文件过大,系统可用空间会突然爆增。sign 通知模式则无需拷贝原来的日志文件。
- 对于按大小切割的场景,
egg-logrotator充分考虑了切割出的日志文件命名问题。新的日志文件会被命名为${final_name}.1。当已有切割文件时,会将原文件自增1,如文件名后缀加1(.log.1->.log.2),直到日志文件数量达到maxFiles最大值后,才会直接覆盖最后一份.log.${maxFiles}。这种实现方式能够最大程度上保证日志的完整性。
小结
日志切割是完善 Node.js 服务可观测性的重要前提,是实现日志可视化检索、日志监控告警和全链路日志分析的前置条件之一。
本文对通用的日志切割原理进行了阐述,展开说明了 Node.js 应用中两种常用的日志切割方案及其背后的实现机制,并对两种实现方案进行了优劣对比。希望给大家在 Node.js 的生产实践中带来启示和帮助。
参考资料
本文发布自 网易云音乐前端团队,文章未经授权禁止任何形式的转载。我们一直在招人,如果你恰好准备换工作,又恰好喜欢云音乐,那就 加入我们!